ElasticSearch 角色
| 节点类型 | 节点作用 | 节点配置参数 | 默认值 |
|---|---|---|---|
| master node | 是一个主节点,负责创建删除索引等操作,开启后即所有的节点都可以竞选主节点,主节点存在的位置,也被称为是一个事务角色层 | node master | true |
| data node | 数据节点,用来存储 master 节点存储的数据的节点,处理数据相关的节点,用来处理数据的 CRUB 操作,对数据进行聚合、搜素,数据节点的操作大部分是 I/O 操作 | node data | true |
| ingest node | 提取节点,具有数据预处理的能力,可以拦截 Index 的请求,可以对数据进行转换,所有的节点都是 Ingest Node | node ingest | true |
| Coordinating Node | 协调节点,负责接收客户端的请求,然后发送到合适的节点,并且会将节点返回的数据汇聚到一起返回给客户端,也就是说会是一个前台,用来接收用户的请求,进行分配,起到了路由的作用,并且要清楚后端 master shards 的位置 | 无 | 设置 master data ingest 全为 false |
| Maching Leanning Node | 机器学习节点,用于运行作业和一些处理机器学习 API 请求 | node ml | true 需要 enable x-pack |
kubernetes logs
传统日志管理系统工作架构
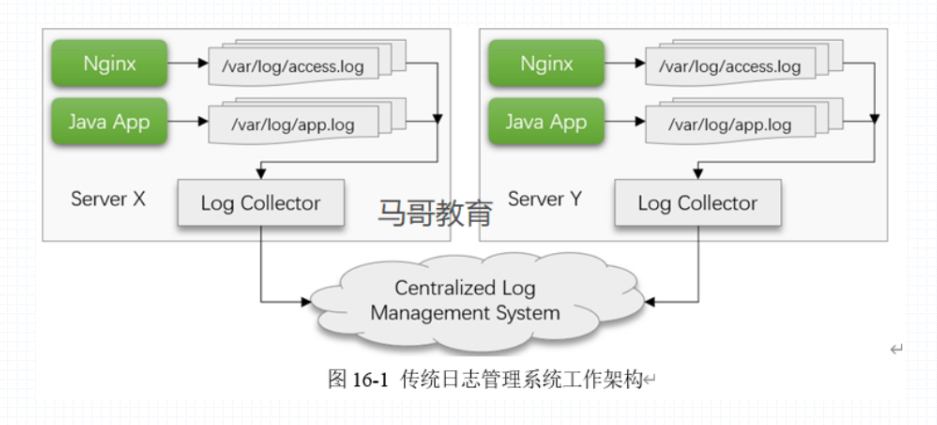
通过日志收集器,例如 filebeat 在节点上收集日志,然后发送给 Centralized log management system,例如 elasticsearch 进行存储,再通过 web ui 的窗口显示。日志管理的功能,再 log collector 中会进行日志的收集,日志的聚合,日志的切割,日志的存储,最终实现日志的传输,传入到 centralized log management system 集中式日志系统,实现用户基于 lucene 搜索引擎进行搜索。
容器化日志管理系统工作架构
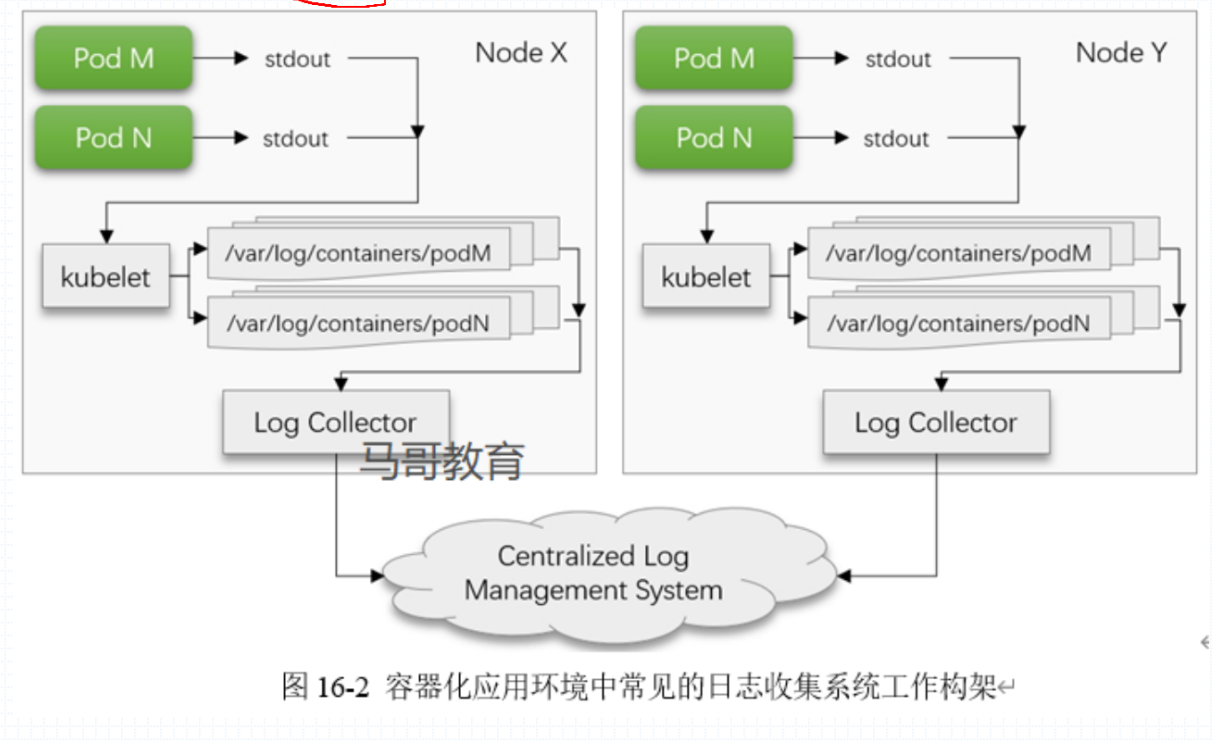
收集容器日志的方式
- 通过 Pod 中运行的 sidecar 共享容器的 filesystem 共享前台输出的日志。
- 通过 Pod 运行中产生的日志信息,kubernetes 会默认存放到
/var/log/containers/pod_name目录中的日志文件中再通过 log collector 来收集日志。
容器环境中应用的应用程序
日志收集通过 fluent-bit,日志的管理通过 elastisearch 或者是 Loki 实现日志的管理查询操作,图形化的图表显示是通过 kibana 或者是 Grafana 来图形化显示。
fluentd 虽然也是云原生的产品,但是过于重量级,所以在后来出现了 fluent-bit 来取代 fluent,当然 filebet 只是早期并且是存在于基础架构中的日志收集器,通常不会作用在容器的环境中。
Promtail 是一种新生的日志收集管理器。
通常的组合也就是 Promtail | Loki | Grafana,或者是通过 Elasticsearch | Fluent-bit | Kibana,新生的架构就是前者称为 PLG,后者称为 EFK。
收集层级
- 收集 Pod 中应用程序的日志
- 收集 kubelet 的日志
- 收集节点级别的日志
Fluent 与 Fluent bit
Fluentd
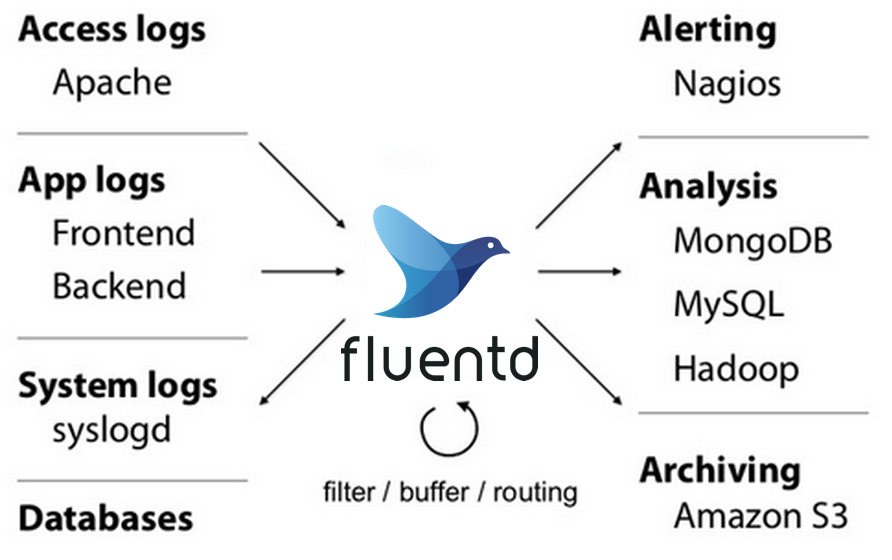
同样也是一款应用在云原生之上的日志收集器,但是相比较与 fluent-bit 更加的有重量,在 2011 年研发出世。与 logstash 类似支持各种的 ruby 语言开发的各种插件。https://docs.fluentd.org/ 各种插件网址 https://www.fluentd.org/plugins 可以为某个特定的数据流打上特定的标签。
fluent bit 的数据管道
fluent-bit 支持在 input、parser、filter、output 实现插件功能的整合。
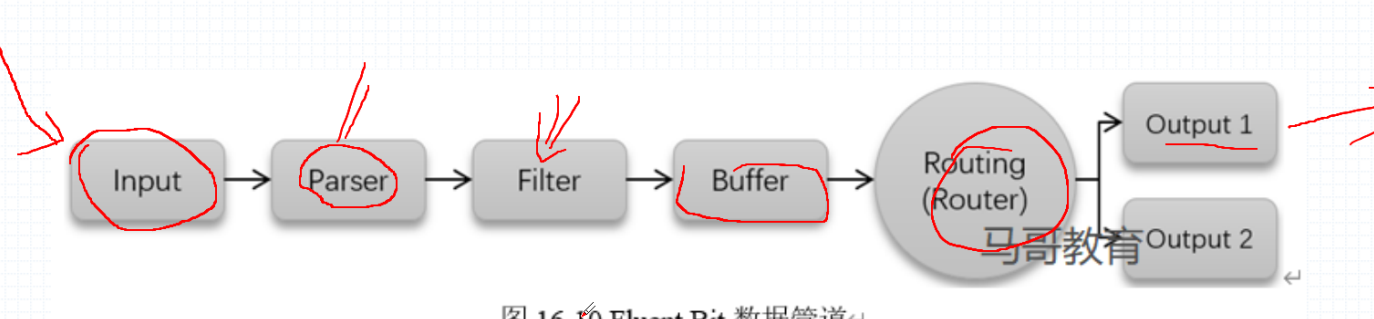
input 收集日志,用来指定各种日志的所在位置,常见的插件有 tail 也就是跟踪日志的尾部做出操作。
parser 对日志的数据进行切片,进行分析,有 logformat 操作,对日志进行筛选通过正则做操作。
filter 针对特定的输入端日志进行格式化进行过滤,移除数据,附加 Pod 以及 namespace 的名称,也就是会附加标签,fluentd 是没有此功能的。
buffer 对 filter 过滤的数据进行缓冲缓冲传入到 routing 中。
routing 路由到指定的 output,路由也是通过 hash 算法,通过计算存储的分片找到指定的 node 节点。
output 输出到指定的存储端。
在 kubenertes 中 ElasticSearch 的运行角色
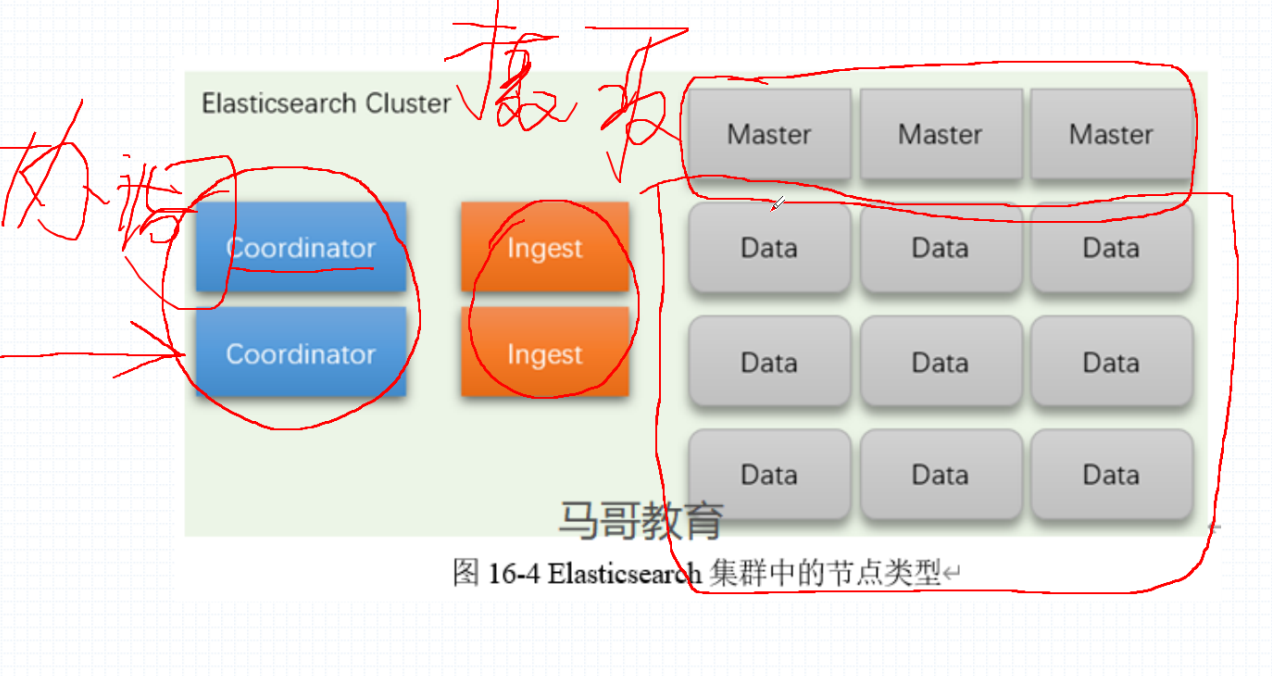
在 kubernetes 中运行的 EleasticSearch 是进行分层的,并且是单独运行的 Pod,每个功能或者是角色都会单独运行,这样保证了运行的效率。
在各种角色中需要的资源各不相同,例如 data 最主要的就是 I/O 资源的消耗,ingest 摄取节点摄取数据是同故宫预处理管道进行预处理,然后才会发送到后端,Coordinator 仅仅只是一个接收数据的作用。
ElasticSearch 索引流程
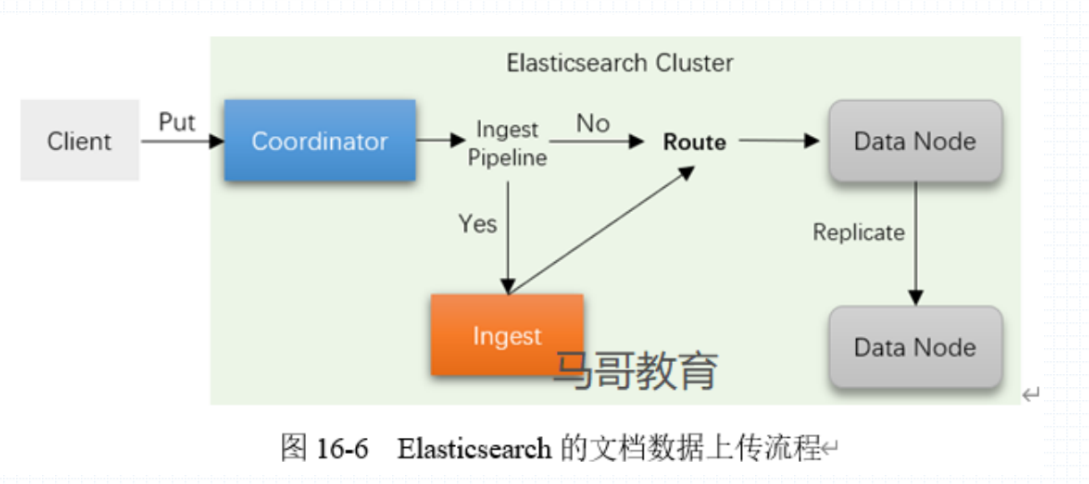
用户发送 Put 请求,也就是要修改 ElasticSearch 中的数据,Coordinator 协调节点会首先受到这一请求,随后发往 Ingest Pipeline 来判断是否需要进行预处理,如果需要就会通过 Ingest 来预处理用户发送的 Put 请求中的数据,将其改为后端的 master shards 可以识别并进行存储的数据,如果不需要预处理,那么就直接发送到 Route 来实现路由的过程,路由实现的过程是通过对数据进行 hash 运算,然后对运算结果进行节点数的取模,计算到数据存储的节点,然后进行修改。当 Master shards 所在的 Data Node 上的数据修改完成后,会发送 Replicate 来要求其他的 Data Node 同步这个数据。
也就是说 Coordinator 可以在 kubernetes 中不存在,Ingest 也可以不存在,然后直接通过 master 节点来进行路由,并进行预处理,因为每个节点默认的 Ingest 就是开启的。
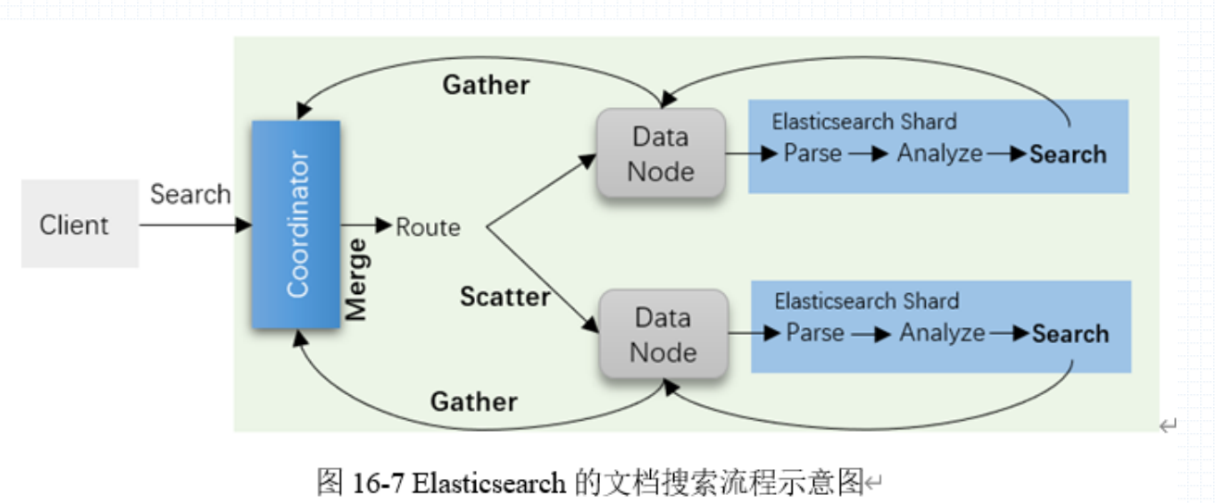
查询请求发送到 Coordinator 协调节点上,协调节点会转发用户发送的 Search 请求,通过路由的转发找到 Master Shards 所在的 Data Node 节点,然后进行路由,对于 Lucnen 而言,每一个分片都是一个完整的数据,随后就会实现查询。Lucnen 进行查询时会首先对用户输入的关键词进行切片(parse)、分析(analyze)最后对分析出的数据执行 search 操作,然后对查询出的内容进行 TF/IDF 打分,最后筛选。
存在一个特殊条件,就是 Lucnen 会存在一个 Boosting 的操作,也就是可以对自定义的提权结果进行提权,即使打分过低,那么通过 Boosting 提权后,也会变成排名靠前的结果。
范例,kubernetes logs 部署方案
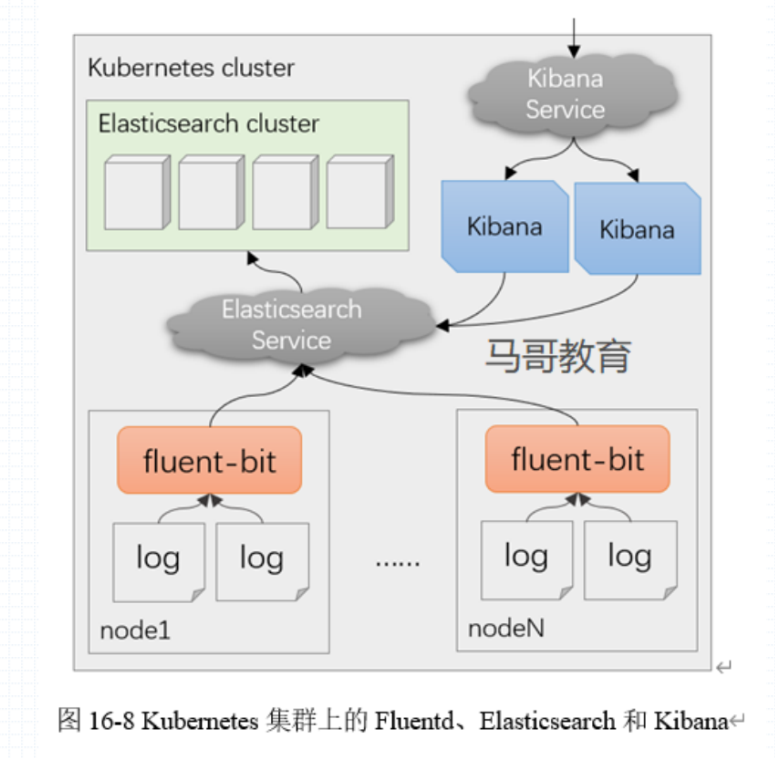
在每个节点上运行一个 fluent-bit 软件来收集节点上的日志,收集完成后统一发送到指定的 Elasticsearch Service,ElasticSearch Service 收到数据后会转发到后端的 ElasticSearch Cluster 集群。同样的,Kibana 如果想要实现图形化的显示,那么也需要通过 ElasticSearch Service 查询到 ElasticSerach Cluster 中的数据进行图形化的图表显示。
部署注意事项
如果是使用 helm 的方式来安装 ElasticSerach 那么安装的版本为 stable 的更倾向于单机来运行,bitnami 组织生产的 helm charts 更适用于生产环境中。
在 kubernetes 中使用的堆内存大小,其中的 1G 内存会被其他的线程占用,并不是全部的都会应用到 ElasticSerach 中。
部署完成后可以查看到 ElasticSerach 运行的 namespace 中的 service 资源,同样也会存在 ElasticSerach 集群中运行的各个角色之间为了保持互相通信而创建的 Service 资源。
启动完成后通过 curl 命令来请求集群中的 elasticsearch 的 health 或者是其他的来进行查看集群的生命状态检测。
部署
- 安装 elasticsearch
https://artifacthub.io/packages/helm/bitnami/elasticsearch
- 安装 kibana
https://artifacthub.io/packages/helm/bitnami/kibana
- 安装 fluent-bit
https://artifacthub.io/packages/helm/fluent/fluent-bit
扩展
- 安装 logstash
https://artifacthub.io/packages/helm/bitnami/logstash
logstash 配置
input: |-
http { port => 8080 }
filebeat 配置
[OUTPUT]
Name http
Match *
Host logstash.elasticsearch.svc.cluster.local. #指定 logstash
Port 8080 #指定开放的端口
Format json