存储系统分类
- 非结构化存储,存储为文件格式,例如日志的文件
- NFS
- Block 输出出来并没没有文件锁,RDB(Ceph分布式复制块设备)
- Filesystem NFS HDFS(Hadoop Filesystem)需要了解一下分布式文件系统
- 半结构化存储,有特定格式,但是在 schema 上并没有很严格的要求,例如自带字段和数据的,也就是 key:v ,也可以进行逐级嵌套, 称为 NoSQL Database
- k/v(键值对格式) redis tikv
- Document(文档存储) MongoDB,ElasticSearch
- Colume Family:Hadoop Database 是运行在 Hadoop 上的 HBase
- GraphDB(图示存储):Neo4j
- TSDB(时序存储)
- 结构化存储,必须要存储到结构中,schema 要求严格,TiDB(兼容 MySQL 协议,原生分布式)
- 老家伙能够存留下来的原因,主要是因为数据强一致性,也就是 ACID
- 事务的支持
- 数据的热区会集中在某些表或者是库中
请求路由机制,需要了解整个分布式的地图,当然当用户发起写操作,那么就会通过这个请求路由分发,但是这种方式会导致读取数据比较麻烦。
ElasticSearch
与其他的半结构化存储不同的是,elasticsearch 提供了一个查询的 API 接口,是以搜索引擎闻名,多维度的存储系统。可以存储文本以及 k/v 数据。是一个文本存储的数据库,并且必须要序列化称为 json 的格式,且在 elasticsearch 的任意节点都可以查询到该文本数据。
端口作用
9300/tcp Cluster Peer 是提供集群服务
9200/tcp Client API 是提供给客户端的
elasticsearch 插件
通过 elasticsearch-plugin 工具来获取插件,默认会通过网络找到指定的插件。
例如 elasticsearch 的管理界面,也就是会展示 elasticsearch 的索引 type 等,原生不支持 head。
了解一下 icu 的插件,可以直接在
官方站点如下
https://www.elastic.co/guide/en/elasticsearch/plugins/7.10/intro.html
索引与分片
索引实际上就是分片在逻辑上的命名空间,一个分片是底层的一个工作单元,并且仅保存了全部数据的一部分,分片实际上就是 lucene 的一个实例也是一个完整的搜索引擎,文档是被存储和索引到分片内,并且应用程序时直接与索引进行交互并不是与分片进行交互。
elasticsearch 是直接将分片分发到集群各处的,并且如果集群规模在扩大或者是缩小时,会自动的进行迁移分片,还是会让分片均匀的分配在集群中。一个分片可以是主分片或者是副分片,索引内的任意文档都会归属于一个主分片,也就是说主分片的数量决定了索引的存储容量。
范例,创建索引并查看集群健康状态
PUT /blogs
{
"settings" : {
"number_of_shards" : 3, //创建的分片数量
"number_of_replicas" : 1 //指定在节点上创建的副本数量
}
}
查看集群状态
{
"cluster_name": "elasticsearch",
"status": "yellow", //查看到为 yellow 因为 ES 集群中只有一个节点,且表示主分片工作正常,但是副分片没有创建,因为同时创建在一个节点上是没有意义的
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
当存储分片的主机宕机后,那么该主机上的分片会被迁移到其他的主机上,如果指定的分片的副本数量大于节点数量,那么就会出现 es 集群状态为 yellow 状态的现象,因为无法满足节点可以正常运行分片的情况,此时需要将指定的 number_of_replicas 改为与节点数量相对应的数量。
文档的路由
如何存储的文档?
当索引一个文档时,那么需要存储到主分片中,elasticsearch 如何知道该文档应该存储到那个主分片中,答案是肯定是非随机的,因为如果是随机的,那么找文档时就找不到指定的文档了。
需要通过计算 shard = hash(routing) % number_of_primary_shards 来得出文档的存放分片位置,routing 字段的内容是一个可变值,默认为文档的 id,number_of_primary_shards 记录了主分片的数量,对该数量取余,得到的就是存放文档的主分片 ID,并且下次要找到文档直接通过该 ID 找到指定的文档即可。
在使用文档那么是如何找到对应的文档?
例如有三个节点,三个节点上各存放主分片以及副本分片,用户无法确认来请求哪个节点,所以就由集群中的 coordinting node 称为协调节点,也就是集群中的主节点,用来接收文档的调用请求,并转发到指定应该响应文档调用请求的节点。并且是通过递归的方式找到目标。
工作步骤
读取文档
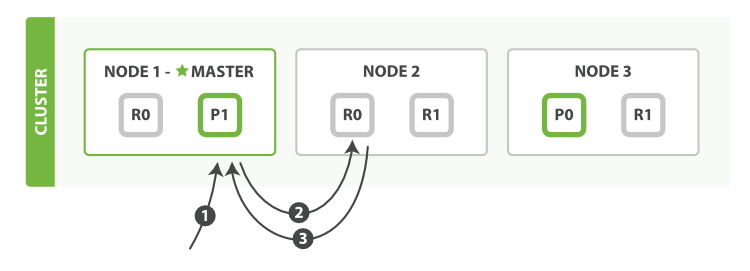
1、客户端向 Node 1 发送获取请求。
2、节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 Node 2 。
3、Node 2 将文档返回给 Node 1 ,然后将文档返回给客户端。
新建文档
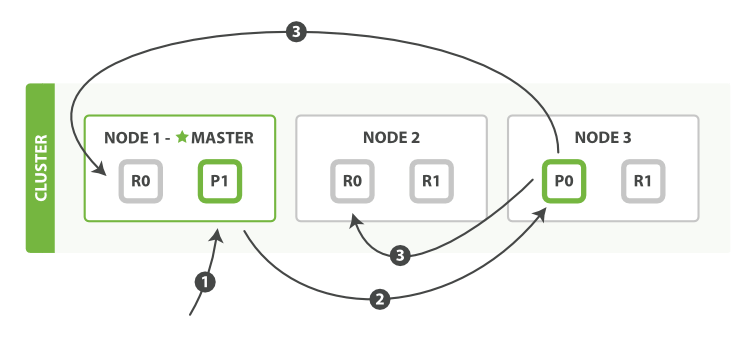
- 客户端向
Node 1发送新建、索引或者删除请求。 - 节点使用文档的
_id确定文档属于分片 0 。请求会被转发到Node 3,因为分片 0 的主分片目前被分配在Node 3上。 Node 3在主分片上面执行请求。如果成功了,它将请求并行转发到Node 1和Node 2的副本分片上。一旦所有的副本分片都报告成功,Node 3将向协调节点报告成功,协调节点向客户端报告成功。
更新文档
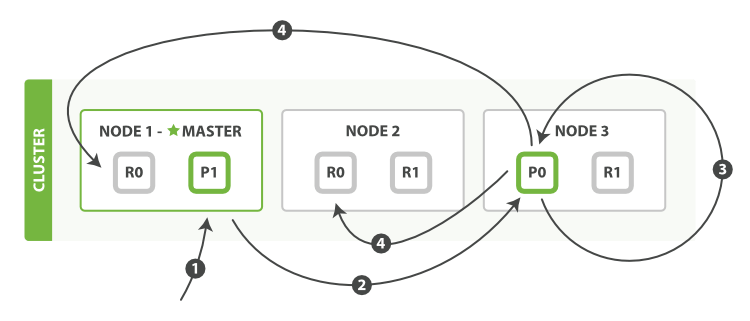
- 客户端向
Node 1发送更新请求。 - 它将请求转发到主分片所在的
Node 3。 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
ElasticSearch 集群健康状态
root@node2:~# wget -qO - 127.0.0.1:9200/_cluster/health|jq
{
"cluster_name": "dingchen.local",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 8,
"active_shards": 16,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
在访问 elasticsearch 的 http 服务中的 _cluster/hhealth 路径中查看到的 status 字段中显示着集群分片的健康状态,有三种状态:
- green 代表集群中的分片全部都运行正常
- yellow 代表集群中的主分片运行正常,但是副本分片没有全部运行正常,集群仍然可以正常的响应用户的请求
- red 无论是主分片还是副本分片都运行不正常
ElasticSearch 生态
elasticsearch 就是基于 lucene 的基础来延申开发出的一个可以根据后端日志格式的查询日志内容的搜索前端。与其同时延申出的还有另一个产品称为 solr。
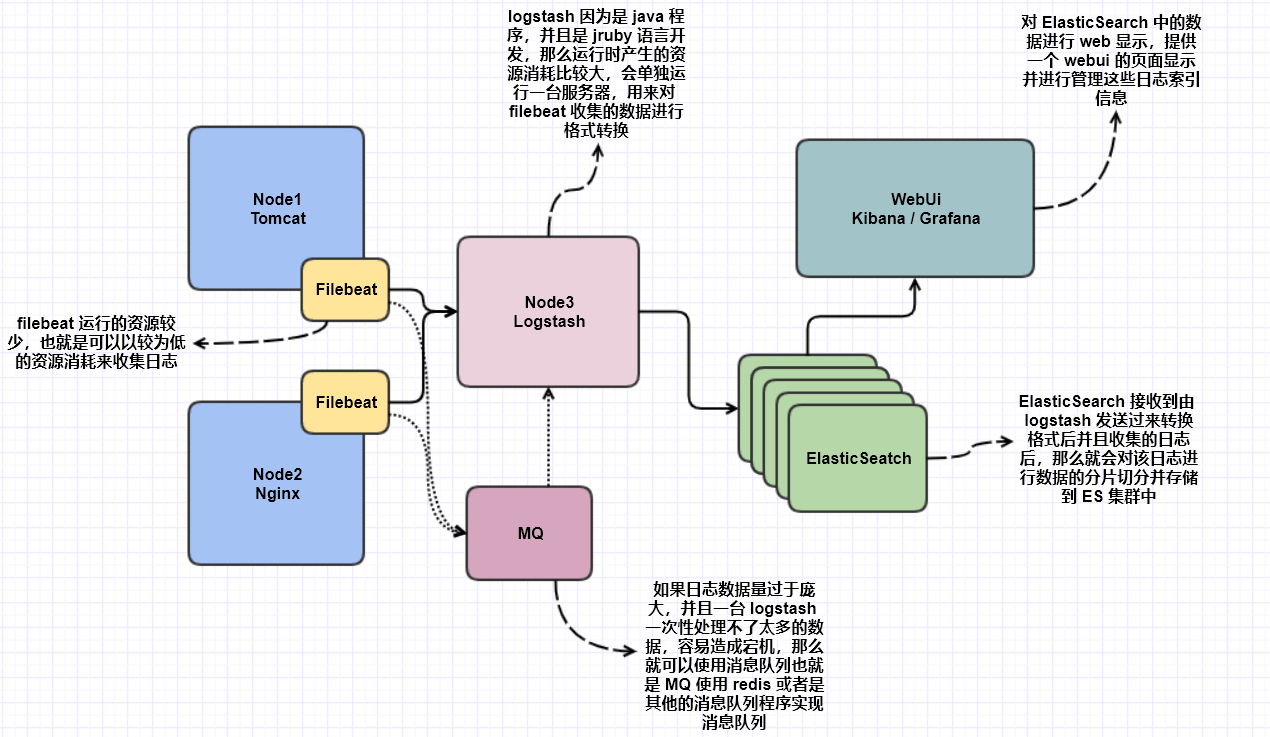
这种组织方式就称为 Elastic Stack,并没有包含后端的 MQ,仅仅是包含了自己的软件内容。
收集日志,是通过在服务上部署一个日志的抽取器 beats,并且仅仅只是日志的抽取,然后装入到单独运行的 logstash 进行格式转换,最后 logstash 发送到 ES 中,ES 再将 http 转换为 web ui 的格式,也就是借助 kibana。
如果收集日志量过大,那么就需要搭建 kafaka 或者是 redis 做消息队列,也就是 MQ 队列。并且可以将不同的日志来发送不同的队列,然后发送给不同的 logstash 进行格式转换,转换完成后发送到 ES 集群中,因为 ES 中的标签都是进行分片冗余的,所以会进行数据的同步。
ElasticSearch 的 api 数据来源
ETL 组件装入
必不可少的需要 ETL 组件,也就是会通过 exporting 将日志进行输出,然后通过 transistion 进行格式转换为 ElasticSearch 可以识别的格式 load 到 ElasticSearch 中。
常用工具如下:
- beats:filebeat
- logstash
- scratch
- fluentd
- fluent-bit
通过爬虫爬取数据装入到其中
搜索引擎的组件
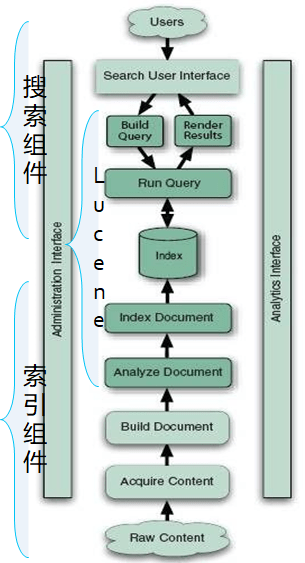
搜索组件
搜索组件,向用户提供关键词,并将用户输入的关键词转换为 lucene 可以识别的一个内容。Search User Interface 是提供给外部用户的 API 接口,ElasticSearch 默认提供的是一个 REST FUL 风格的 HTTP 的 API 接口,用户可以使用 Curl 命令查看,也可以通过借用其他的组件,例如 Kibana 来生成图形化显示的管理界面。
Build Query 是将用户从图形化界面或者是 REST FUL 风格接口输入的关键字转换为 ElasticSerarch 可以查看的关键搜索字,Run Query 执行 Build Query 转换格式后的关键字。
索引组件
索引组件,当用户通过 ETL 组件或者是爬虫接收到数据后,那么就会通过自己原生支持的功能进行切词并转换为倒排索引并转入到索引库中等待用户的查询。Analyze Document 进行切词,Index Document 生成倒排索引存储起来。
Page Rank 算法
在 lucene 搜索引擎中,使用的是 page rank 算法,这也是 google 搜索引擎使用的算法这种算法举个例子就像三个页面共有 30 分,起初都有十分,但是之后当用户在 A 页面跳转到 B 页面,那么A 页面也会给 B 页面一分,依次类推,假设到最后是 A 页面得分最高,那么 A 页面就会理所当然的在搜索页面的第一个。
倒序索引概念
索引在 ElasticSearch 中是一个逻辑概念,称为一个数据的集合,Type 是一组数据的组合。type 类似于 Mysql 中的 table 概念,文档的概念被称为 Document,对应的也就是 mysql 中的 row。每个索引就相当于一个数据库的概念。
可以将所有的数据放置到不同的 index 中,然后在 index 中对数据进行 type 的分类。
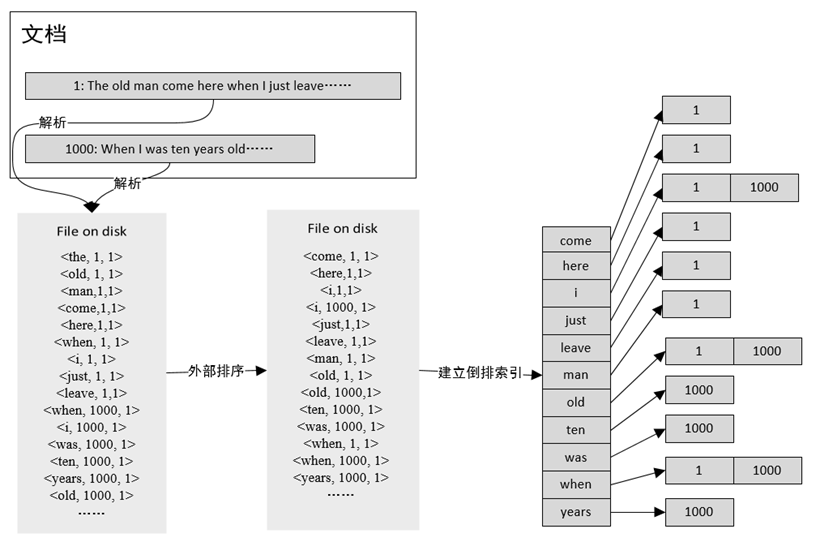
- 对文档进行切分成单个的关键词
- 进行倒序排序,也就是将出现次数越多的排到越后
- 最后建立倒叙索引,会通过哪些词的存在然后链接到指定的文档标号中,当用户输入关键词时,会根据关键词来找到文档的位置
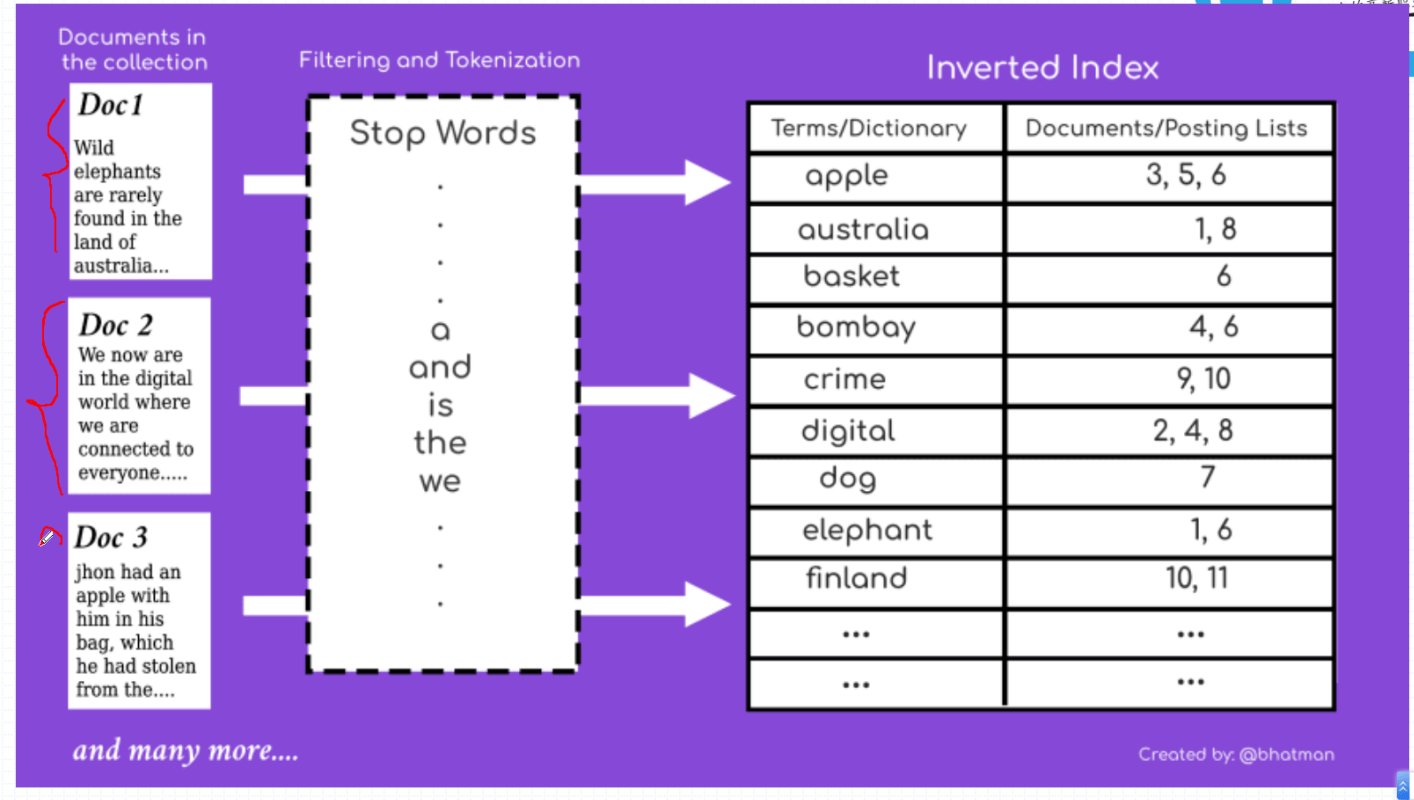
对词进行排序,然后通过词来找到所在的文档,并不是根据文档来找这个词有没有。与其他关系型数据库不同的地方可能在这个地方也体现出来了,也就是说 elasticsearch 会查看这个词所在的文档,在关系型数据库会查看文档中有没有这个词。
如果有多个关键词满足了多个文档那么就会取出交集,然后对交集中的文档进行打分,取出第一个文档,支持模糊匹配,也就是可以支持忽略大小写的匹配。
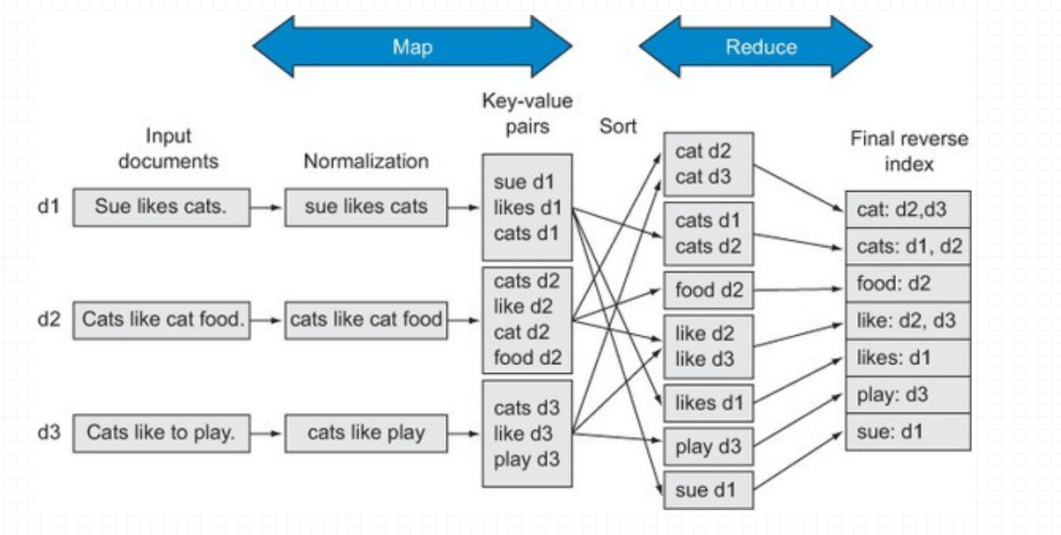
整个分析的过程称为 map 和 reduce 的过程,在搜索引擎中大小写并不是关键的,所以会在 Normalization 中进行大小写替换,如果出现同义词那么也会显示
tf-idf 算法,tf 就是统计这个词在该文件中出现的频率出现越高那么得分越高,idf 这个词在其他文件出现的次数出现的次数越多,那么 tf 的得分越低,是一个词语普遍重要性的度量。
map 转换为指定的格式,进行排序和整理
reduce 进行折叠,也就是将相同类型的整合到一起
java 的种类
java 2 SE
会被解码成 bytecodes 然后运行在 JVM(java vm)
开发环境就是 JDK 也称为 java 的工具箱
并且可以通过 maven 或者是 ant 来构建构成项目,也就称为 build
java 2 EE
ES 的安装
会通过域来找到所在域的所有主机
会通过 cluster.name 来找到所在域的所有主机,并且会通过 nodename 来找到 node。
指定 network.host 中的地址,指定监听的服务地址。
discovery.seed_hosts 找到指定的节点
cluster.initial_master_nodes 指定节点中的 master 节点,通过选举产生的,
jvm.options 文件,指定 jvm 的内存使用。
ELK 就是 ElasticSearch Logstash Kibana,后来引入了 Filebeat 用来收集日志中的内容。即使是停止了 beat 重新开启那么还是会按照上次读取到的文件位置继续读取。
对 CPU 和内存的压力很大,所以在生产环境中不能进行与其他的生产服务器同时运行。
集群配置
cluster.name 集群名字一样那么就会在一个集群中
path.data 存储的数据位置,最好将 data 和 logs 放入不同的存储设备
path.logs 指定日志的位置
network.host 监听的 IP 地址
discovery 发现集群成员节点,zen 就是发现协议 ping 就是一个指定的动作,unicast 早期支持单播和多播,然后指定集群中的节点
discovery 指定集群中的主节点最少要有几个节点 elastic search 才能正常运行
工作原理
就是通过在所有节点中选举一个主节点,负责整个集群的状态 green yellow red 以及各 shards 的分布方式
jvm.options
Xms1g 初始化时需要分配的堆内存
Xmx1g 最大使用的内存
curl 命令的使用
集群配置:
elasticsearch.yml配置文件:
cluster.name: myels
node.name: node1
path.data: /data/els/data
path.logs: /data/els/logs
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1", "node2", "node3"]
discovery.zen.minimum_master_nodes: 2
discovery:发现集群成员节点:zen发现协议,单播
RESTful API: CRUD(Create, Read, Update, Delete) curl -X ‘://:/?‘ -d ‘‘ :json格式的请求主体; GET,POST,PUT,DELETE 特殊PATH:/_cat, /_search, /_cluster
<PATH>
/index_name/type/Document_ID/
curl -XGET ‘http://10.1.0.67:9200/_cluster/health?pretty=true' curl -XGET ‘http://10.1.0.67:9200/_cluster/stats?pretty=true' curl -XGET ‘http://10.1.0.67:9200/_cat/nodes?pretty'
curl -XGET 'http://10.1.0.67:9200/_cat/health?pretty'
创建文档:
curl -XPUT
特殊PATH:/_cat, /_search, /_cluster
文档:
{"key1": "value1", "key2": value, ...}
elasticsearch 中设置的索引位置
是通过 curl 127.0.0.1:9200/_cat/indices 命令可以查看到的内容,filebeat 会自带一个指标名称,然后通过 elasticsearch 可以查看到,需要创建一个索引名称可以匹配到的才可以查看到这个指定的索引下的数据。
RestFul 指标
relocating_shards 迁移的分片数量
initializing_shards 只要不为 0,那么就是有新创建的索引存在
unasslgned_shards 集群知道有这个分片,但是在节点上找不到,就例如在本机创建一个主分片和副本分片,那么就会出现这个状态
number_of_pending_tasks
number_of_in_flight_fetch 业务的数量,与内部分片迁移有问题
stats 集群级别的统计信息 states helths stats settings(可以直接通过 put 进行提交并修改)
索引级统计信息
[index_nmae]
需要关注的是挂起任务,也就是在 _cluster/pending_tasks 中查看挂起的任务。
_cat api 接口也是比较重要的信息。
官方文档中会有最佳实践的文档。
ES 的重要参数
cluster.name
node.name
path.plugins 加载插件目录,子目录就是插件名称
path.data
单播组播的问题
zen 的协议,官方不建议使用组播。
gateway
集群完全重启后,至少要有几个节点启动后,那么整个集群才会启动数据的恢复。
recover_after_time 等待多长时间,expected_nodes 多少节点全部上线
elasticsearch-head
该组件时 elasticsearch 原生支持的一款图形化,elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到elasticsearch(5.0版本后不支持此方式),也可以安装成一个独立webapp。elasticsearch-head插件是使用JavaScript开发的,依赖Node.js库,使用Grunt工具构建,所以等会我们要安装elasticsearch-head,还需要先安装Node.js和Grunt。
filebeat
通常是用来收集日志的工具,可以将输出源指定为 logstash 也可以指定为 elasticsearch,指定为 logstash 时,那么显示的内容将会被格式化,并且由 logstash 来提交格式化后的信息。
如果直接提交到 elasticsearch,那么也不会进行格式化,而是直接会存储到 elasticsearch 的存储库中。
在 filebeat 中也可以指定 input 和 output 的输出,也是通过模块来指定。
logstash
能够进行日志的转换,提供了清洗添加内容以及转换格式,并且该工具是一个框架,并且实现的功能很多,也是以插件的方式来实现的。基于 jruby 的语言来实现,所以占用的空间太大。
通过 filebeat 或者是直接通过文件的方式 input 到 logstash 内部的 filter 进行格式化转换或者是删除一些字段信息,之后 output 到 elasticsearch,然后由 elasticsearch 提交到 kibana 进行图形化显示。
也就是说通过 filebaet 收集到的日志并不会直接传送给 elasticsearch 然后显示,而是传输到 logstash 进行格式化转换后才会发送给 elasticsearch。
如果要使用 systemd 来运行 logstash 来连接 redis,那么必须要使用 user 为 root 来运行,因为系统用户 nologin 的关系,所以导致不会向 redis 中写入数据。
logstash 定义
input 来自标准输入,支持直接加载日志文件
- beats 自己监听端口,让 beats 自己将日志数据发送过来
- file 直接读取文件,如果是使用这种方式,那么可以通过使用
start_position选项来指定从什么位置来读取日志文件 - redis 是可以指定 redis 来读取日志文件
filter 通过过滤插件的功能进行过滤,也可以更改格式转换后的内容,可以将内容转换为自己想要的内容,在 filter 中使用一些替换的字符或者是格式化的字符,实际上就是通过正则进行匹配内部的数据,然后进行格式化输出的。
- grok 进行过滤插件过滤,并更改日志内容,是通过 grok 进行匹配的,在 grrk-patterns 中有定义正则进行匹配文本,字段的格式 {IP:realip} IP 是一个正则的名称,realip 是显示的名称。
- date 插件,更改时间戳
- mutate 更改字段名称
- geoip 更改字段的内容
output 输出到指定的 elasticsearch 或者是其他的显示界面中
- elasticseatch 插件可以切分索引
logstash 正则
在 /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/ 目录中存储着 logstash 可以使用的正则以及相关的组合完成的模块,在 grok-patterns 文件中定义着一些基础的正则表达式,其他的文件都是将该文件中基础的正则组合到一起形成的。
logstash 插件
geoip 是将源 IP 地址映射到 geo 中,映射到地理位置中,也就是会映射到 iana 组织中的 IP 地理位置的映射关系。也就是会通过 maxmand 组织提供的,但是仅仅只会精确到地域。返回的结果就是经度和纬度指定的位置。
count 是每次取数据的格式,是每次取出的数据次数。
geoip 需要指定 target 和 source ip 地址,用来输出对应地理位置的结果。在每个字段中都会存储着 groip.location 字段用来存储经度和纬度
原生支持 json 格式的数据
grok 插件会对每个数据进行正则匹配,所以格式化日志时,会浪费过多的资源。
如果应用程序可以指定 json 格式,可以直接输出。
日志类型不同的情况
在 filebeat 收集时对其打上标签,然后在 logstash 中的 fileter 或者是 input 中通过 if 进行判断。
logstash 支持通过 if 判断也支持通过 and or 进行取交集差集进行判断。
需要将 fields.logtype 转换为 [fileds][logtype] 进行判断,这种模板称为 DSL 语言。
范例
实现 filebeat logstash elastsearch 结合
filebeat 配置
root@node2:~# cat /etc/filebeat/filebeat.yml |grep -Ev "#|^$"
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
- type: filestream
enabled: false
paths:
- /var/log/nginx/access.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
host: "192.168.1.30:5601"
output.logstash:
hosts: ["192.168.1.30:5044"]
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
logstash 配置
input {
beats {
port => 5044
//对外开放的端口,需要在 filebeat 中指定
}
}
filter {
grok {
match => {
"message" => "%{HTTPD_COMBINEDLOG} \"%{IP:formart_ip}"
//进行格式化转换
}
remove_field => "message"
//删除 message 字段
}
}
output {
elasticsearch {
hosts => ["http://node1:9200/","http://node2:9200/","http://node3:9200/"] //指定 elasticsearch 的位置
index => "logstash-%{+YYYY.MM.dd}" //指定 index 的名称,这里指定为 logstash+时间戳
}
}
elasticsearch 配置
cluster.name: dingchen.local
node.name: node2.dingchen.local
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["node1.dingchen.local","node2.dingchen.local","node3.dingchen.local"]
cluster.initial_master_nodes: ["node1.dingchen.local","node2.dingchen.local","node3.dingchen.local"]
实现 filebeat logstash 消息队列
logstash 配置
更多配置查看 https://www.elastic.co/guide/en/logstash/7.11/plugins-inputs-redis.html
input {
redis {
batch_count => 1 //每次读取返回的日志信息
data_type => ["list"]
db => "15"
host => "192.168.1.33"
port => 6379
key => "filebeat"
threads => 5 //启用的线程数量
}
}
filebeat 配置
更多配置查看 https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-redis.html
# -------------------------------- Redis Output --------------------------------
output.redis:
enabled: true #指定是否开启
hosts: ["192.168.1.33:6379"] #指定 redis 的主机位置
key: filebeat #指定键名
#password: #可以指定 redis 的密码
db: 15 #指定数据库位置
datatype: list #指定键名的类型
实现 filebeat 打标 logstash 判断
filebeat 打标
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
logtype: access
- type: log
enabled: true
paths:
- /var/log/nginx/error.log
fields:
logtype: error
logstash 判断
input {
redis {
host => "172.18.0.70"
port => 6379
password => "magedu.com"
db => 0
key => "filebeat"
data_type => "list"
}
}
filter {
if [fields][logtype] == "access" {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message","beat"]
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
}
output {
if [fields][logtype] == "access" {
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
//document_type => "httpd_access_logs" //此选项将被废弃,取而代之的是 %{foo} 的字符串,来动态的生成后缀,而不是通过 decument_type 来决定存储的位置,可以通过这个 foo 来指定为不同的索引
}
} else {
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
//document_type => "httpd_error_logs" //此选项将被废弃
}
}
}